咱们普通人一听这名儿,脑子估计都大了,啥叫“全基因组扩增”?听着就像实验室里那些白大褂鼓捣的高深玩意儿。其实没那么悬乎,咱把这词儿掰开了揉碎了说,你就明白了。说白了,就是咱们身体里的DNA,那玩意儿是咱最核心的遗传密码,但有时候样本太少,比如就一根头发丝儿,或者就一个细胞,那点DNA根本不够机器去读取分析的。咋整?就得想办法把这“一丁点儿”的DNA给“复制”出一大堆来,而且还得保证复制出来的东西跟原来的一模一样,不能走样。这个过程,就叫“全基因组扩增技术”。
你得这么想,这技术就像是生物界的“复印机”,而且是那种最高端的、能把一个芝麻粒儿大小的原件,给你高清无损地放大成一张A1海报的神器 -1。搞科研的人为啥离不开它?因为很多时候他们面对的就是“芝麻粒儿”啊!比如犯罪现场的一丢丢血迹,或者想研究一下肿瘤里头单个细胞到底有啥猫腻,没有这技术,根本玩不转。这复印机好不好使,关键看两点:一是能不能把边边角角都给复印全了(咱这儿叫覆盖度),二是复印的时候别自己瞎发挥、添油加醋(咱这儿叫保真度)。今天咱就唠唠这神器背后的门道。
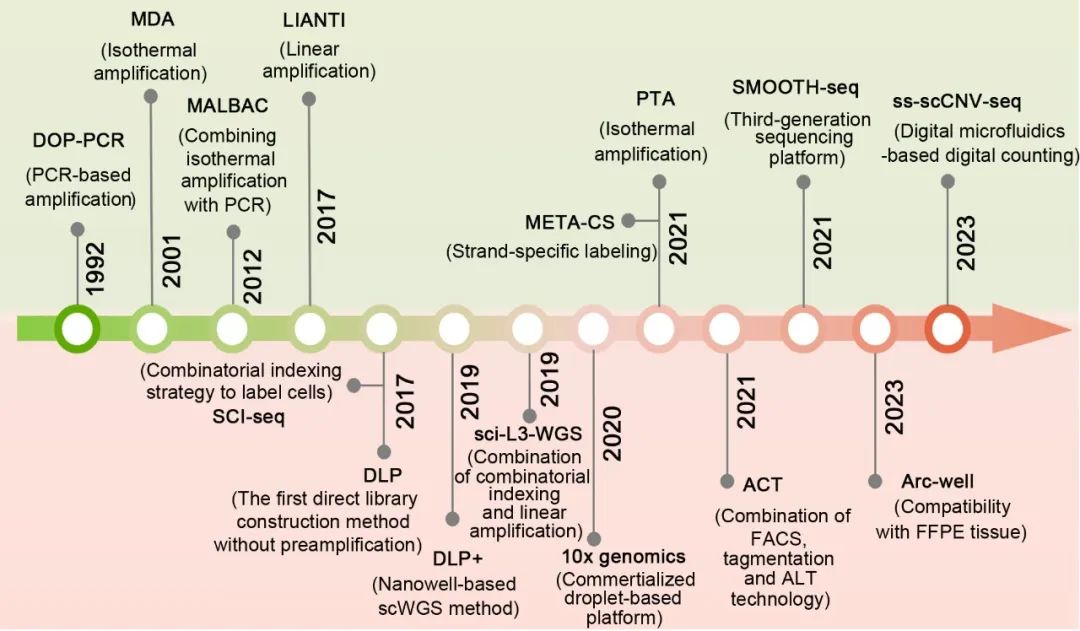
这技术从1992年那会儿就有了雏形,刚开始的时候其实挺糙的。最早的方儿法有点像咱们上学那会儿用的那种特别low的复印机,你想复印个卷子,结果出来的东西黑一块白一块,有些字儿还给你扩变形了。那时候用的主要是基于PCR(聚合酶链式反应)的扩增技术,比如简并寡核苷酸引物PCR,也就是DOP-PCR -2。这玩意儿吧,它用的那种引物,就像是拿了一把万能钥匙去开门,虽然大部分门都能捅咕两下,但不见得能把门完全打开。它扩增出来的东西,片段短,而且特别挑地方,有些基因区域它喜欢,就拼命扩;有些区域它不喜欢,就给人家漏掉了。这就导致最终的产物覆盖度很低,有时候连10%都不到 -2。你说这要是在刑侦上,恰好漏掉的那个区域就是破案的关键,那不抓瞎了吗?而且那时候用的聚合酶,就是那个干活的“工人”,校对能力不行,经常把字儿给抄错了,所以单核苷酸变异啥的,基本没法儿用它来精确检测 -6。
后来吧,技术迭代了,出了个狠角色,叫“多重置换扩增”,英文缩写MDA。这个可厉害了,它用的不是那种怕热的高温聚合酶,而是一种叫Phi29的、在恒温下干活儿且耐力贼强的“老师傅” -1。这师傅有个绝活,叫“链置换”,它一边复制,一边把前面的链给顶开,自己接着往前走,这么一来,它能一口气复制出老长老长的片段,有时候能达到100kb那么长,比那些老方法长了几百倍 -1。更牛的是,这师傅还有个“校对眼”,自带3”->5“的外切酶校正功能,一边干活一边检查,要是发现贴错了字母,立马改回来,保真度比那些Taq酶高出一千倍 -1。这样一来,用MDA扩增出来的DNA,用来做SNV(单核苷酸多态性)分析就靠谱多了。可以说,全基因组扩增技术发展到MDA这一步,算是真正解决了“复制的像不像”这个大难题。
但MDA是不是就完美无缺了呢?也不是。这师傅虽然活好,但有个毛病,就是干活儿的时候有时候会“偏科”。有些基因组区域它特别喜欢,就使劲儿在那儿复制;有些区域它不太感冒,就敷衍了事。这就导致了扩增的均一性不够好,也就是覆盖的深浅不一,在做拷贝数变异(CNV)检测的时候,背景噪声就比较大,让数据分析的人很头疼 -2。就好比你去拍全班合影,MDA这个摄影师总是把焦点对在前排那几个长得好看的同学身上,后排的同学虽然也在照片里,但都是虚的,你想数清楚后排站了几个人、谁跟谁挨着,那可就费劲了。
为了解决这个“偏科”的毛病,科学家们又开始琢磨新招儿。2012年前后,出来一个叫MALBAC的新技术 -2。这名字听着挺绕口,它的原理其实挺巧妙。它有点像把MDA的长处和PCR的短处给“中和”了一下。它的引物设计得很特别,能保证在第一轮扩增的时候,新合成的DNA链末端会自己互补,形成一个“环”,这样一来,这些新链就不会再被当作模板继续无限制地扩增下去了 -6。这就相当于给扩增过程加了个“刹车”,让扩增从“指数爆炸”变成了“准线性增长”,大大减少了早期扩增的偏好性。所以MALBAC做出来的产物,均匀度特别好,既能有比较高的覆盖度(能达到93%左右),又能兼顾CNV和SNP的检测 -2。现在在辅助生殖领域,比如胚胎植入前的遗传学诊断,MALBAC就用得特别多 -6。你想啊,要在移植前对一个只有几个细胞的胚胎进行遗传病筛查,那必须得准,不能出一点岔子,这技术就派上了大用场。
不过,故事到这儿还没完。即便有了MDA和MALBAC这些好用的方法,实际应用中还是会有“漏网之鱼”。有些特别复杂的遗传变异,比如某些和并指畸形相关的基因突变,用常规的全外显子测序可能根本查不出来。为啥?因为外显子测序只盯着占基因组2%的编码区看,而那些致病的变异可能藏在更广阔的“垃圾DNA”里头。这时候就得请出真正的“终极武器”——全基因组测序。2025年有个特别典型的例子,北京家恩德运医院用全基因组测序,发现了被传统方法漏掉的HOXD13基因变异,成功找到了那些隐匿的致病变异,这才给患者家庭一个明确的诊断 -3。这说明啥?说明样本扩增只是第一步,扩增完之后你怎么去分析、看多宽的视野,同样至关重要。这也从侧面给搞基础研究的提了个醒:如果你的全基因组扩增技术本身有偏差,那后续再牛的测序平台,测出来的数据也是歪的。
最近这两年的进展更是让人眼花缭乱。咱们中科院的青岛能源所,在2023年搞出了个叫iSGA的新技术 -7。这技术是在Phi29聚合酶的基础上,通过蛋白质工程改造,弄出了一种叫“HotJa”的高活性酶。用它来扩增单个细菌细胞,覆盖度最高能达到99.75%!这是个什么概念?以前扩增细菌,因为它的细胞壁难破、DNA含量极低,能有个30%的覆盖度就烧高香了,现在直接拉到99%以上,几乎等于把整个基因组给“复印”全了 -7。这对研究那些没法在实验室培养的“难搞”微生物来说,简直就是打开了新世界的大门。而且这是咱们国产的技术,成本比进口的便宜了11倍,性能还高出两倍,这才是实打实的突破,解决了“卡脖子”的问题 -7。
还有一个挺有意思的新思路,是上海交通大学医学院在2025年公开的一项专利。他们针对MDA扩增不均一的问题,没在扩增过程本身死磕,而是在扩增之后加了一个“质检”环节 -9。用qPCR检测多个不同染色体上的位点,看看扩增得均不均匀。只有那些通过了质检、证明自己“均匀性良好”的样本,才会被拿去建库测序。这就好比招工的时候不仅要看你有没有人来,还得先考你个试,及格了才让你进厂拧螺丝。这种方法虽然简单粗暴,但在实际操作中却能有效筛掉一大批不合格的样本,保证最终数据的可靠性。
所以说,全基因组扩增技术从1992年走到现在,从最初那个模糊不清的“复印机”,变成了现在高精度、高覆盖度、甚至还能自我质检的“智能系统”。搞科研的之所以离不开它,是因为它直接决定了我们能不能从那些微小的样本里,掏出最真实、最完整的生命秘密。不管是追查罪犯、筛查遗传病,还是研究肿瘤的狡猾多变,都离不开这幕后英雄。
最后再唠点实在的,这技术虽然越来越牛,但你真要是做实验,还是得长个心眼。别以为买来最贵的试剂盒就万事大吉了。你得搞清楚你的目的是啥:是做CNV筛查,还是找SNP突变?如果是前者,可能DOP-PCR或者优化过的MALBAC就够用;如果是后者,那Phi29聚合酶系的MDA技术肯定是首选。千万别搞混了,不然拿着测SNV的数据去做拷贝数分析,那结果准保让你哭不出来。还有啊,做单细胞实验的时候,无菌操作和防止污染是红线中的红线。毕竟就那点模板,进去一丁点儿外源DNA,扩增出来的可能全是噪音。干这行,拼的不光是脑子,还有那份细致和耐心。